【AWS】Amazon Monitron(モニトロン)のデータをKinesis経由でS3にいれる
最終更新日: 2024/04/11 9:27am
こんにちは。小高です。
桜がまだまだ見頃です。
今日は、Amazon MonitronデータをKinesis Data StreamからS3にエクスポートする方法をご紹介します。
Amazon Monitronの概要は、以前のブログをご参照ください。
リンク:【AWS】Amazonの産業向けソリューション Amazon Monitron(モニトロン)レポート 2023/12/07
Amazon モニトロンのその後
先のブログでMonitronを設定してみましたが、弊社のようなITの会社には「振動する機械」というものがありません。
継続して実験してみないことにはお客様にご紹介もできないので、どうしたもんかと思っていたところ、私のサブ開発機がガラガラいうではありませんか!
そこでMonitronセンターを貼り付けました。

一応、波形がわかる程度に振動しています。

取得したデータをS3にいれたい
Monitronの「売り」は「機械の異常検知を丸投げできる」ところにあります。
そのため、サービスの建て付けが「AWS管理コンソールとMonitronのモーバイルアプリにクローズした仕様」になっています。
ですが、「せっかく取得したデータなんだから再利用したい」と思うのが人情です。
クラスメソッドさんが「リンク:Amazon MonitronのデータをKinesis Data Streamsにエクスポートしてみた」という記事を公開してくれていますので、
・まずは、クラスメソッドさんのやり方でKinesis Data Streamにデータをエクスポートする
・つぎに、LambdaでS3バケットにデータをいれる
というところまでやってみます。
Amazon Monitronは、現時点(2024/4/5)で日本リージョンで利用できないため、以前のブログで利用した北米(バージニア)リージョンで作業します。
まずは、クラスメソッドさんのやり方でKinesis Data Streamに入れる。
クラスメソッドさんのやり方にしたがって、まずはKinesis Data Streamを作成します。
バージニア北部リージョン(Amazon Monitoronを設定したリージョン)であることを確認します。

データストリームを作成していきます。ここではStream名をMonitronStreamにしました。
テスト目的なので、シャードは1つだけにします。

Kinesis Data Streamが作成されました。

Kinesis Data Streamができたら、Amazon Monitronのメニューに戻り、Start Live Data Exportを選択します。

Kinesis Data Streamを選択するセレクトボックスでは、先ほど作成したMonitronStreamを選びます。
選択したら、Start Live Data Exportしましょう。

これでMonitronからKinesis Data Streamにデータが流れ始めます。
Monitronは1時間に1回だけ計測値があがってくるので、Kinesis メニューからMonitoronStreamを選択して気長に待ちます。
(モバイルアプリから計測してもオッケーです)

しばらくすると、ポツポツでデータが流れて来ます。

データを見てみましょう。
画面にある「データビューワー」タブでシャード(今回は1つと設定した)と開始位置を選択して、レコードを取得を押すとデータがでてきます。
開始位置=最新とするとデータが見られないのが何故かわかりませんが、今回はS3にデータを送るつもりなのでそのままいきます。

リンクをクリックしてデータをみます。
JSONを指定すると以下のようになります。
コピーボタンでコピーはできるのですが、ダウンロードはできない感じです。

下がデータのサンプルです。
{
"timestamp": "2024-02-29 08:31:38.896",
"eventId": "226",
"version": "2.0",
"accountId": "99999999",
"projectName": "Monitoron Test",
"projectId": "XXXXXXXX",
"eventType": "measurement",
"eventPayload": {
"siteName": "Servers",
"assetName": "開発機2",
"positionName": "Front",
"assetPositionURL": "https://app.monitron.aws/#xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
"sensor": {
"physicalId": "XXXXXXXXX",
"rssi": -69
},
"gateway": {
"physicalId": "XXXXXXXXX"
},
"measurementTrigger": "periodic",
"sequenceNo": 226,
"features": {
"acceleration": {
"band0To6000Hz": {
"xAxis": {
"rms": 10.1812
},
"yAxis": {
"rms": 0.7353
},
"zAxis": {
"rms": 1.4179
}
},
"band10To1000Hz": {
"totalVibration": {
"absMax": 0.1102,
"absMin": 0,
"crestFactor": 3.0398,
"rms": 0.0362
},
"xAxis": {
"rms": 0.0168
},
"yAxis": {
"rms": 0.0144
},
"zAxis": {
"rms": 0.0287
}
}
},
"velocity": {
"band10To1000Hz": {
"totalVibration": {
"absMax": 0.1497,
"absMin": 0,
"crestFactor": 2309.4011,
"rms": 0.0648
},
"xAxis": {
"rms": 0.0374
},
"yAxis": {
"rms": 0.0374
},
"zAxis": {
"rms": 0.0374
}
}
},
"temperature": 12.052
},
"models": {
"temperatureML": {
"previousPersistentClassificationOutput": "HEALTHY",
"persistentClassificationOutput": "HEALTHY",
"pointwiseClassificationOutput": "INITIALIZING"
},
"vibrationISO": {
"isoClass": "CLASS1",
"mutedThreshold": null,
"previousPersistentClassificationOutput": "HEALTHY",
"persistentClassificationOutput": "HEALTHY",
"pointwiseClassificationOutput": "HEALTHY"
},
"vibrationML": {
"previousPersistentClassificationOutput": "HEALTHY",
"persistentClassificationOutput": "HEALTHY",
"pointwiseClassificationOutput": "INITIALIZING"
}
}
}
}
バンド0-6000Hzに対して、10-1000Hzのデータをモニタリングしていることがわかります。
6000Hzということは12000Hzでのサンプリング(DFT)のはずなので、性能のよいセンサーが入っているのですね。
振動については専門でないので深入りできませんが、異常検知に際して定数成分をカット(=変動成分のみ使う)し、ノイズ除去の意味合いで高周波数を取り除いているようです。
データの最後の部分、
"models": {
"temperatureML": {
"previousPersistentClassificationOutput": "HEALTHY",
"persistentClassificationOutput": "HEALTHY",
"pointwiseClassificationOutput": "INITIALIZING"
},
"vibrationISO": {
"isoClass": "CLASS1",
"mutedThreshold": null,
"previousPersistentClassificationOutput": "HEALTHY",
"persistentClassificationOutput": "HEALTHY",
"pointwiseClassificationOutput": "HEALTHY"
},
"vibrationML": {
"previousPersistentClassificationOutput": "HEALTHY",
"persistentClassificationOutput": "HEALTHY",
"pointwiseClassificationOutput": "INITIALIZING"
}
}が異常検知の結果のようです。
MLとあるのは機械学習(Machine Learning)のはずなので、温度と振動について(なんらかの)MLアルゴリズムで異常の有無を判断しています。
ステータスがINITIALIZINGになっているのは、(このデータを取得したときには)「まだ学習中」という意味と思えます。
振動レベルを評価するのに、ISOとMLを基準にしているのも、この学習期間確保のためかもしれませんね。
Kinesis DatastreamからLambdaでS3へ
「何語だ?」という見出しになりましたが、いよいよ上のデータをS3に入れましょう。
Kinesis Data StreamへのデータエントリーをトリガーにしてAWS LambdaでS3にいれる、というやり方にします。
まずは、適当なバケットにmonitronというフォルダーを作成しておきます。

AWS公式「Lambda でデータを処理する」に従い、KinesisからLambdaを実行するためのroleを作成します(IAMメニュー)。

下の画面では、
・エンティティタイプ=AWSサービス
・ユースケース=Lambda
にします。

許可の追加では、AWSLambdaKinesisExecutionRoleを追加します。

ここではlambda_kinesisという名前でroleを保存しました。

つぎに、AWS公式「Lambda でデータを処理する」に従ってLambda関数を作ります。
プログラミング言語はpythonを使います。
リージョンがバージニア北部になっていることを確認して、関数を作成していきます。

関数の作成画面では、
・設計図:kinesis-process-record-python
・名前: monitoron_data_to_S3
ロールは先ほど作成した、lambda_kinesisを使います。

Kinesisトリガー画面では、
・先ほど作成したMonitoronStream
・Actvate Trigger(作成後にActivateされる)
・バッチサイズ(Lambdaへ渡されるレコード数)=1
・position=LATEST(公式より)を選びます。

コードタブにサンプルコードを作ります。
取得したMonitronデータをJSON形式でダンプするだけのものです。
import base64
import json
'''
lambda handler
'''
print('Loading function')
def lambda_handler(event, context):
print("Received event: " + json.dumps(event, indent=2))
for record in event['Records']:
# Kinesis data is base64 encoded so decode here
payload = base64.b64decode(record['kinesis']['data']).decode('utf-8')
print("Decoded payload: " + payload)
return 'Successfully processed {} records.'.format(len(event['Records']))
動きを確認するためにテストイベントを作成して、上のコードを実行してみます。
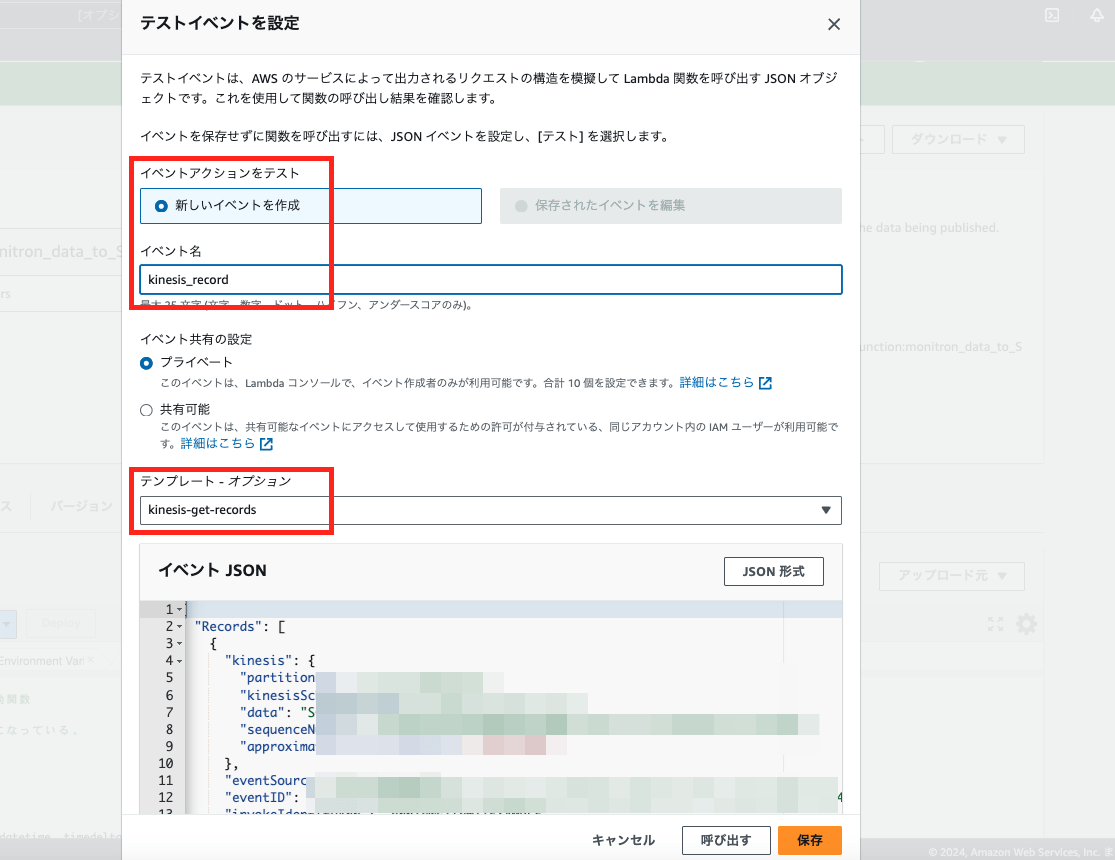
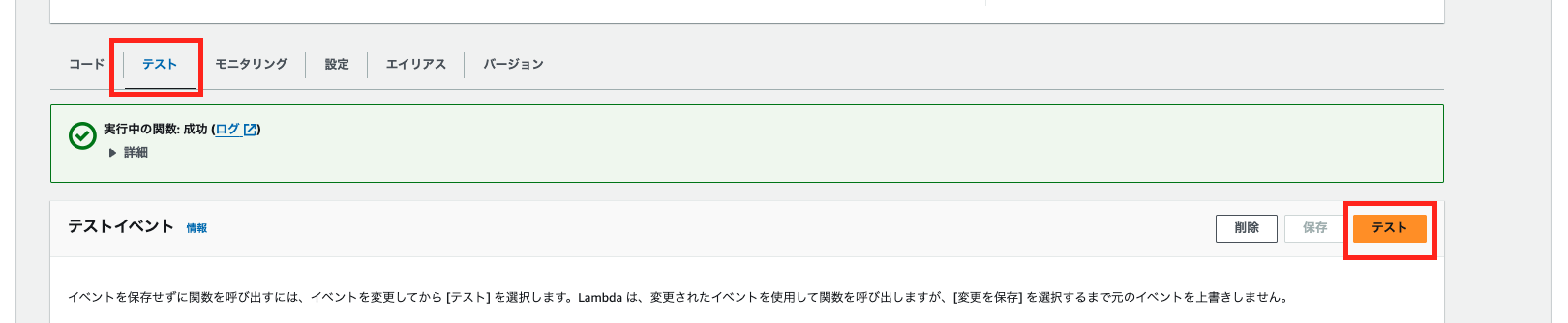
さて。
ようやく準備ができたので、Kinesisをトリガーに設定します。

トリガーの追加では、Kinesisを選び、データが流れてくるMonitronStreamを選択します。
Activate Trigger、Batch size=1、Starting Position=LATESTとします。

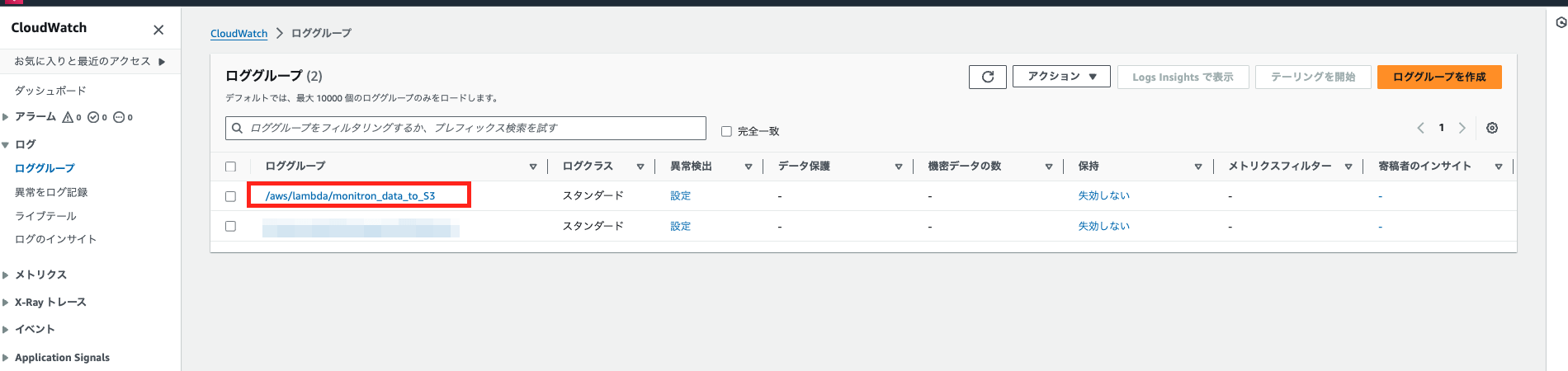
これでLambdaにKinesisトリガーが追加されたので、Kinesis Data Streamにデータが入ったタイミングで(Lamda関数によって)Cloud Watchログにデータがダンプされます。

モバイル端末から測定を実行すると、先ほど確認したClouWatch Logグループ内のログストリームに、ダンプしたMonitronデータが確認できると思います。(下はイメージ)

さぁ、いよいよこの流れを使って、MonitronデータをS3にいれていきましょう。
バケットをフォルダーを再掲しておきます。
早速Lamda関数を書き直したいところですが、その前に、LambdaからS3にデータを書き込むためのアクセス許可を追加しておきましょう。
以下では、バケット名を[bucket name]とします。
先ほど作成した、lambda_kinesis roleにインラインポリシーを追加します。(IAMで作業しています)

インラインポリシーには、以下のポリシーを直接JSONで設定してしまいます。
[bucket name]のところは、適宜変更してください。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowStatement1",
"Action": [
"s3:ListAllMyBuckets",
"s3:GetBucketLocation"
],
"Effect": "Allow",
"Resource": [
"arn:aws:s3:::*"
]
},
{
"Sid": "AllowStatement2",
"Action": [
"s3:ListBucket"
],
"Effect": "Allow",
"Resource": [
"arn:aws:s3:::[bucket name]"
],
"Condition": {
"StringLike": {
"s3:prefix": [
"monitron/*"
]
}
}
},
{
"Sid": "AllowStatement3",
"Action": [
"s3:GetObject"
],
"Effect": "Allow",
"Resource": [
"arn:aws:s3:::[bucket name]/monitron/*"
]
},
{
"Sid": "AllowStatement4A",
"Effect": "Allow",
"Action": [
"s3:*"
],
"Resource": [
"arn:aws:s3:::[bucket name]/monitron/*"
]
}
]
}
Lamda関数では、バケット名、フォルダー名を環境変数として設定しておくことにします。
S3_BUCKET=[bucket name]
S3_PREFIX=monitron

Monitronデータは、Monitronフォルダーの下に日付別フォルダーを作成して保管するようにします。
また、保管する際のファイル名は日付と時間、アセット名とポジションを入れるようにします。
lambda_function.pyを以下のように修正したら完了です。
import os, json
from datetime import datetime, timedelta
from zoneinfo import ZoneInfo
import base64
import boto3
'''
lambda handler
'''
def lambda_handler(event, context):
tokyo = ZoneInfo("Asia/Tokyo")
for record in event['Records']:
payload = base64.b64decode(record['kinesis']['data']).decode('utf-8')
print("Decoded payload: " + payload)
# ファイル名の決定
bucket = os.environ['S3_BUCKET']
prefix = os.environ['S3_PREFIX']
_dt = datetime.now(tokyo).strftime('%Y-%m-%d_%H%M%S')
_fn = _dt
jp = json.loads(payload)
if 'eventPayload' in jp:
if 'assetName' in jp['eventPayload']:
_fn = _fn + '_' + jp['eventPayload']['assetName']
if 'positionName' in jp['eventPayload']:
_fn = _fn + '_' + jp['eventPayload']['positionName']
key = prefix + '/' + datetime.now(tokyo).strftime('%Y-%m-%d') + '/' + _fn + '.json'
# S3へ書き出す
_ret = S3_Put_Object(bucket, key, payload)
if _ret:
print('S3への書き込み完了')
else:
print('S3への書き込み失敗')
'''
S3へデータを書き出す
'''
def S3_Put_Object(bucket, key, content):
s3 = boto3.resource('s3')
b_obj = s3.Object(bucket, key)
response = b_obj.put(Body=content)
ret = False
if 'ResponseMetadata' in response:
if 'HTTPStatusCode' in response['ResponseMetadata']:
if response['ResponseMetadata']['HTTPStatusCode'] == 200:
ret = True
return ret
こんな感じにデータが蓄積します。
保管期間が決まっていれば、S3のライフサイクルルールを設定してストレージクラスを落としたり、削除したりするのがいいと思います。

今回は、MonitronデータのKinesis DataStreamへのエクスポートと、LambdaをつかったS3への書き込みまで一気にご紹介しました。
当初思っていたより、かなり長くなってしまいました。
最後まで読んでくださった方、本当にありがとうございました。
ここまでできれば、データが再利用できるので、また何か進展があれば報告したいと思います。
←「【お知らせ】イー・レンジャーかわら版(2024年4月号: NVIDIAの株価はなぜ高い )を発行しました。」前の記事へ 次の記事へ「【お知らせ】イー・レンジャーかわら版(2024年5月号: Japan IT Week 春にいってきました )を発行しました。」→